
UFC Fight Victor Predictor
Data Centric Approach to the Ultimate Fighting Championship
Setting the Stage
Friday, October 18th, 2019, UFC on ESPN 6 Main Event - Dominick Reyes vs. Chris Weidman Light Heavyweight bout.
Question on everyone's mind was who was going to win the fight?

The only question on my mind was can I train a machine learning algorithm to answer that question for me?
The UFC is a modern day gladiator style competition where two fighters enter the octagon arena to test their hand to hand combat skills against each other to determine who is the superior fighter.

With available historical UFC fight data from (www.UFCstats.com), this information can be used to train a statistical model to predict (with hopefully some degree of certainty) the winner of an upcoming fight.
Of course there are countless unknowns and confounding variables outside the scope of this dataset that will limit the efectiveness of this model, but hey, why not?
Fortunately user Rajeevw on Kaggle developed a webscriping process to pull the data from www.UFCstats.com seen here:
Shout out to you Rajeevw:

Inisde the Data
The dataset contained 5144 total fights ranging from the conception of the UFC in 1993 to mid 2019 when the data was collected.
There are 1915 unique fighters with a median of 3 recorded fights for each.
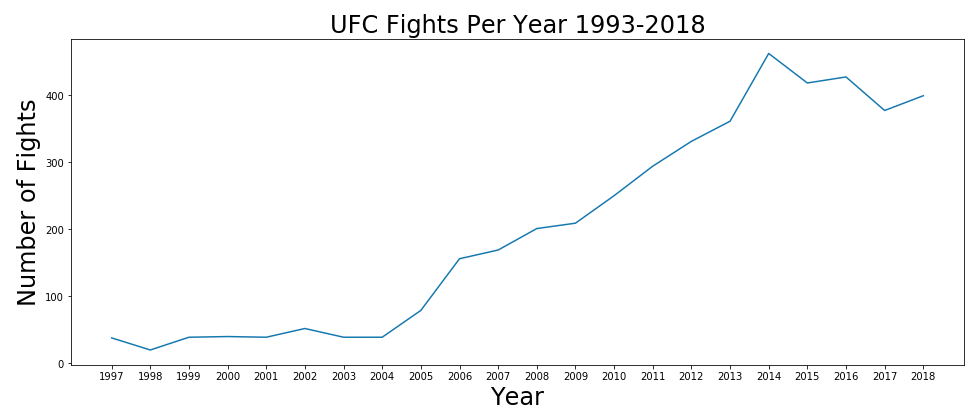
There was a spike in interest in the UFC starting in 2005 which can mainly attributed to the premier of The Ultimate Fighter on Spike TV and the popularity of Monster Energy drinks.

Here is an intial peek at the dataset:
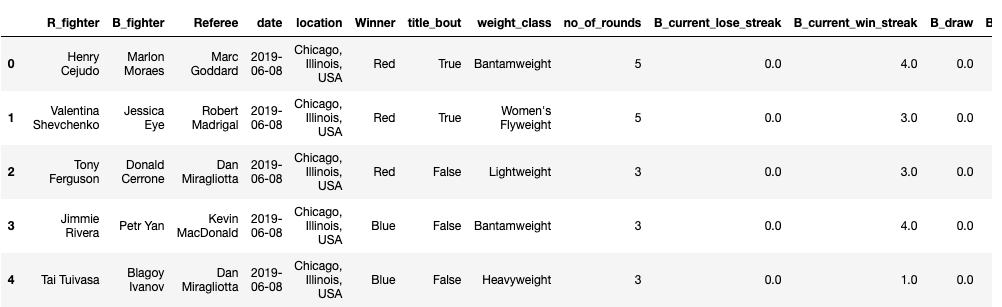
Each row inside this dataset represents a completed fight between two competitors. Their individual stats leading up to the fight are provided as well as the winner of the fight.
There are basic stats such as:
- Age
- Height
- Weight
- Reach
- etc.
But there are also some more interesting behavioral stats given that are more indicative of style such as:
- Punches Attempted / Landed
- Kicks Attempted / Landed
- Takedowns Attempted / Landed
- etc.
I wanted to determine from this data if there are any commonalities / differences of the traits between winners and losers in the UFC and identify key indicators of winning.
EDA - Exploratory Data Analysis
Dataset was split by weight class and grouped into the winners and losers to see if there are any obvious trends right off the bat.
REACH
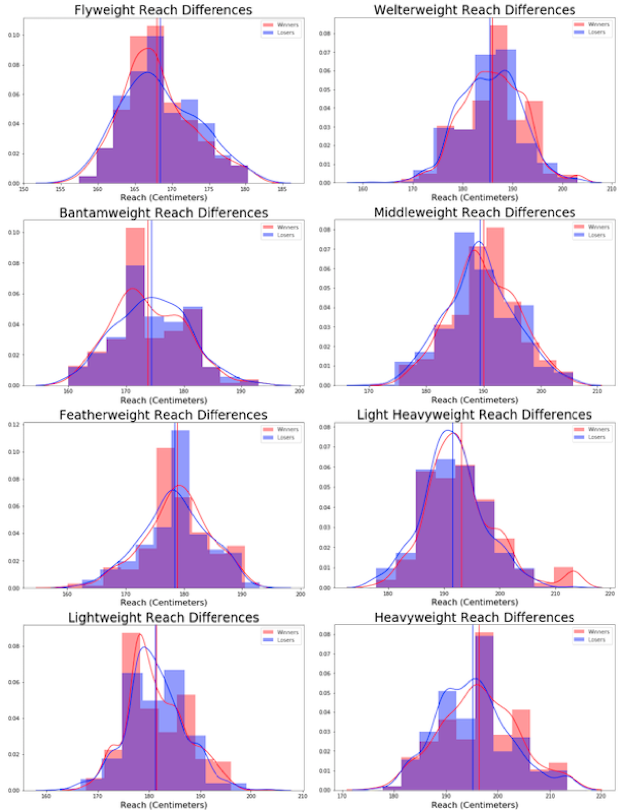
In terms of reach, the winners tend to have longer arms. Which makes intuitive sense since you can strike and engage at a further distance.
HEIGHT

In terms of height, the winners tend to be taller.
AGE

And younger as well.
Results make intuitive sense, but there are underlying complexities that can be uncovered with Machine Learning.
Data Pre-Processing
Prior to any processing, a couple of gaps in the data were identified through EDA. Many of the fighter's reach information was missing as well as a small number of easy lookup values.
Luckily there is a strong correlation between a human's height and arm length:

So I used the K-Nearest Neighbors algorithm to fill in the missing NaN values.
Now the data was filled, it was reconfigured into a single dataframe with winner and losing being the labels of a binary classifier.
This allows us to hone in on the traits of winners and losers.
The dataset was also split with the fights that occured in 2019 to be used as a test validation set and all fights from 1993 to 2018 to be used to train the model.
HOWEVER, this big caveat is that we lose the "matchup" portion as we are looking at the fighters individually versus against a specific opponent.
Modeling
Multiple statistical classification models were tested to see which performed the best for the task at hand.
- Logisitic Regression Classifier
- Random Forest Classifier
- XG Boost Classifier
A grid search was performed on each model to tune the hyperparameters of each model to see which yielded the highest accuracy.
Results during the grid search were logged via the log.py script to record results and parameters.
Results
XGBOOST ended up being the most accurate with a score of ~63%
Here is a snapshot of what the model results look like on some of the 2019 matchup data:
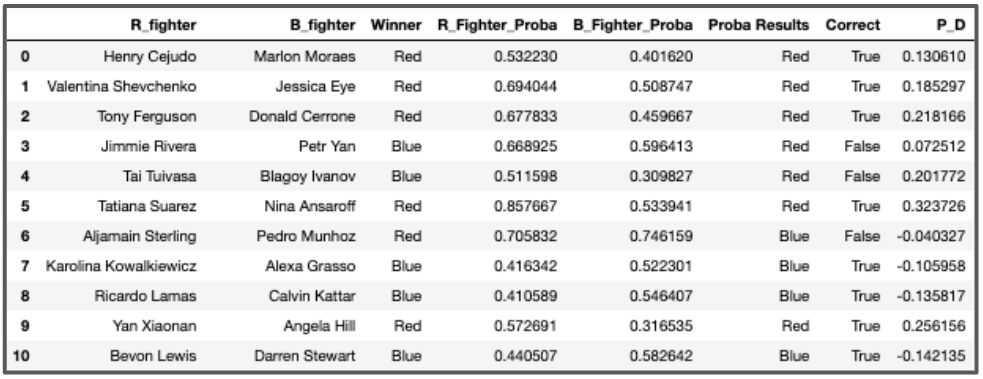
The trained model is used separately on each fighter to determine their individual chance of winning a fight (not necessarily their matched opponent for the fight) and the winning probability is predicted. Those two numbers are compared and used to predict the victor of the matchup.
Most influential characteristics were identified as:
- Age
- Average Opponent Takedown %
- Average Opponent Significant Strike %
- Reach
- Average Headshots Landed

These can be loosely interpreted as:
- Youth trumps experience
- Defense wins championships - how many takedowns and hits you allow is a major factor
- Having a longer reach than your opponent is a big indicator of being the superior fighter
- Headshots tend to be very effective in winning the bout
Back to the Topic
Regarding the Reyes vs. Weidman fight, my model predicted the below:
Dominick Reyes - 60.9% chance of winning a future fight Chris Weidman - 57.6% chance of winning a future fight
Since I was sleep deprived and hyped at the time, I decided it would be a good idea to put money down and put full faith into my model by betting on the fight.
I was rewarded.

Reyes KOed Weidman in the 1:43 into the first round.
Next Steps
Perfomance wise, I definitely like to increase the accuracy. The decision boundary on the classifier can definitely be tuned and potentially adding additional information into the dataset it can make it become a better predictor.
Style wise, I would like to make a nice UX/UI to create an easy to use system.
Link to GitHub
Scope out the latest project updates on my GitHub HERE